
В данном руководстве рассматривается настройка балансировщика HAProxy для распределения операций записи на выделенный сервер и операций чтения между всеми узлами кластера Galera с целью предотвращения ситуацией блокировки (deadlock).
Кластер Galera имеет известные ограничения, одним из которых является то, что он использует оптимистическую блокировку всего кластера. Это может вызвать откат некоторых транзакций. С увеличением числа доступных для записи узлов Master вероятность отката транзакций может увеличиться, особенно если клиенты изменяют сравнительно малый набор данных. Всегда можно повторить транзакцию, и, вероятно, она будет выполнена при повторных попытках, но это увеличит задержку транзакции. Существует ряд архитектурных решений, применяемых в приложениях, которые особенно подвержены частому возникновению ситуации взаимной блокировки (deadlock), например, таблицы последовательностей.
Взаимная блокировка — классическая проблема транзакционных баз данных. Это ситуация, когда транзакции блокируют друг друга таким образом, что дальнейшее выполнение их становится невозможно. Первая транзакция имеет блокировку на некоторый объект базы данных, к которому другая транзакция ожидает доступа, и наоборот. Разрешить подобную ситуацию можно лишь путем отмены хотя бы одной из транзакций. Как правило, всегда можно написать приложения таким образом, что они всегда будут готовы перезапустить транзакции, если произошел откат из-за взаимных блокировок.
Однако у данного решения есть недостатки:
- Возрастает нагрузка на журнал транзакций, так как каждая неудачная попытка будет записана в журнале, включая запись об откате.
- Взаимная блокировка обнаруживается не сразу. Это снижает производительность системы в целом из-за того, что транзакции вынуждены ждать, пока одна из участвующих во взаимоблокировке транзакций не отменится.
- Подобное решение в общем случае отрицательно влияет на масштабируемость системы, поскольку с увеличением нагрузки число взаимных блокировок будет возрастать, причем не линейно. Следовательно, будет расти количество ожидающих транзакций, что в итоге может привести к существенному снижению производительности системы.
В связи с вышеизложенным, следует минимизировать вероятность возникновения взаимных блокировок. В этой статье мы рассмотрим способы снижения риска возникновения взаимных блокировок, возникающих из-за архитектуры кластера.
Статья является переводом и адаптацией англоязычной статьи от Severalnines — разработчика инструмента ClusterControl.
Пример
Приведем простой тестовый пример. Имеется таблица со столбцом и строкой, где хранится число, которое является порядковым номером и регулярно обновляется. Таблица имеет следующую структуру:
mysql> CREATE TABLE `seq_num` ( `number` bigint(20) DEFAULT NULL ) ENGINE=InnoDB DEFAULT CHARSET=latin1
Простой скрипт sequential_update.sh (код скрипта приведен в конце статьи) выполняет последовательное обновление порядкового номера. В этом тесте мы используем уровень изоляции по умолчанию REPEATABLE READ. Теперь давайте запустим его с 10000 обновлений на одном из узлов базы данных в кластере Galera (операции чтения/записи с выделенным сервером):
$ ./sequential_update.sh 10000 single.log
Последние 5 строк вывода будут выглядеть так:
$ tail -5 single.log #9996: 9996 -> 9997 #9997: 9997 -> 9998 #9998: 9998 -> 9999 #9999: 9999 -> 10000 #10000: 10000 -> 10001
Теперь запустим скрипт, подключившись к экземпляру HAProxy, который обеспечивает балансировку нагрузки в кластере Galera с тремя узлами с помощью Round Robin (операции чтения/записи в равнодоступном кластере):
$ ./sequential_update.sh 10000 multi.log ERROR 1213 (40001) at line 1: Deadlock found when trying to get lock; try restarting transaction ERROR 1213 (40001) at line 1: Deadlock found when trying to get lock; try restarting transaction ERROR 1213 (40001) at line 1: Deadlock found when trying to get lock; try restarting transaction
Посмотрим вывод последних 5 строк. Обратите внимание, что порядковый номер (#) не соответствует обновленному значению. Во время возникновения блокировки было пропущено 3 порядковых номера:
$ tail -5 multi.log #9996: 9993 -> 9994 #9997: 9994 -> 9995 #9998: 9995 -> 9996 #9999: 9996 -> 9997 #10000: 9997 -> 9998
Разбор ситуации
Это ожидаемое поведение в кластере Galera. При координации обновлений из нескольких сессий базы данных применяется стратегия оптимистической блокировки, которая предполагает, что все обновления могут выполняться без конфликтов. Если две сессии пытаются изменить одни и те же данные, вторая из них будет отклонена и должна будет повторить транзакцию.
Узел-инициатор может получить все необходимые блокировки для транзакции, но он не имеет представления об остальной части кластера. Таким образом, он оптимистично отправляет транзакцию (или write-set) всем остальным узлам, чтобы посмотреть, смогут ли они ее выполнить.
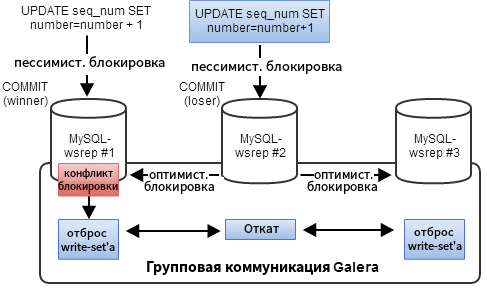
После этого write-set проходит детерминистический сертификационный тест на каждом узле (включая узел отправителя), который определяет, можно ли применить его или нет. Если сертификационный тест не пройден, write-set отбрасывается, а исходная транзакция откатывается. Если тест пройден успешно, транзакция фиксируется, и write-set применяется к остальным узлам.
Решение
В случае, если данные имеют высокий уровень параллелизма операций записи, одним из возможных обходных путей может быть отправка части обновлений, которые создают взаимоблокировки (либо вообще всех обновлений), только на один выделенный узел.
При настройке HAProxy через ClusterControl HAProxy обеспечит балансировку нагрузки между всеми узлами кластера. Чтобы обеспечить отправку всех запросов только на один узел кластера, достаточно изменить стандартную равнодоступную конфигурацию для порта 33306, добавив ключевое слово backup для всех серверов, кроме выбранного. Такую настройку для порта 33307 вы можете видеть в примере из файла /etc/haproxy/haproxy.cfg:
listen s9s1_33307_LB1
bind *:33307
mode tcp
timeout client 60000ms
timeout server 60000ms
balance leastconn
option httpchk
default-server port 9200 inter 2s downinter 5s rise 3 fall 2 slowstart 60s maxconn 256 maxqueue 128 weight 100
server 192.168.0.101 192.168.0.101:3306 check
server 192.168.0.102 192.168.0.102:3306 check backup
server 192.168.0.103 192.168.0.103:3306 check backup
Далее необходимо перезапустить экземпляр HAProxy.
Если вы используете ClusterControl, можете просто послать сигнал HAProxy с помощью kill и позволить ClusterControl восстановить его. Просмотреть, какими процессами управляет ClusterControl, можно в разделе Manage process.
Проверьте, добавился ли порт 33307 к портам, которые слушает HAProxy:
$ netstat -tulpn | grep haproxy tcp 0 0 0.0.0.0:33306 0.0.0.0:* LISTEN 54408/haproxy tcp 0 0 0.0.0.0:33307 0.0.0.0:* LISTEN 54408/haproxy tcp 0 0 0.0.0.0:9600 0.0.0.0:* LISTEN 54408/haproxy
Теперь можно настроить приложения так, чтобы они взаимодействовали с обоими экземплярами HAProxy соответственно. Помните, что для операций чтения следует использовать порт 33306, так как он балансирует нагрузку на все узлы, а для операций записи с выделенным сервером предназначен исключительно порт 33307. HAProxy обеспечит автоматическую обработку отказа узла при сбое «главного узла Master», подключившись к следующему узлу в списке резервных копий.
Если предполагается, что в качестве узла Master будет использоваться только один узел в один период времени, некоторые требования к кластеру можно снизить. Например, уже не так критичен размер очереди на Slave, поэтому можно ослабить механизм Flow Control:
wsrep_provider_options = "gcs.fc_limit = 256; gcs.fc_factor = 0.99; gcs.fc_master_slave = yes"
Это позволяет улучшить производительность репликации за счет снижения частоты событий Flow Control.
Дополнение
Исходный код — sequential_update.sh
#/bin/bash
# Example usage: ./sequential_update.sh [count] [output_file]
COUNT=$1
OUTPUT_FILE=$2
HOST='192.168.0.100' # multi-node
PORT='33306' # multi-node
#HOST='192.168.0.101' # single-node
#PORT='3306' # single-node
USER='mydb'
PASSWORD='password'
DB='mydb'
TABLE='seq_num'
MYSQLBIN=`command -v mysql`
MYSQL_EXEC="$MYSQLBIN -u $USER -p$PASSWORD -h$HOST -P$PORT -A -Bse"
QUERY_TRUNCATE="TRUNCATE TABLE $DB.$TABLE;"
QUERY_INSERT="INSERT INTO $DB.$TABLE VALUES (1);"
QUERY_SELECT="SELECT number FROM $DB.$TABLE;"
QUERY_UPDATE="UPDATE $DB.$TABLE SET number = number + 1;"
cat /dev/null > $OUTPUT_FILE
$MYSQL_EXEC "$QUERY_TRUNCATE"
$MYSQL_EXEC "$QUERY_INSERT"
## Looping
for (( i=1; i<=$COUNT; i++ ))
do
val1=$($MYSQL_EXEC "$QUERY_SELECT")
$MYSQL_EXEC "$QUERY_UPDATE"
val2=$($MYSQL_EXEC "$QUERY_SELECT")
echo "#$i: $val1 -> $val2" >> $OUTPUT_FILE
done