![]() На днях мы начали выбор решения для управления данными, которое бы поддерживало высокую производительность на операциях INSERT. Данная задача достаточно часто встречается в различных информационных системах, например, в системах биллинга с большим количеством пользователей и учетных объектов, в системах обмена мгновенными сообщениями, в системах аналитической обработки данных map-reduce. Все данные задачи характеризуются тем, что в них большое количество операций вставки новых объектов в БД и огромный размер БД, при этом обработка данных может производиться как в онлайн так и в пакетном режиме. Если провести параллель в сторону большинства традиционных сайтов (например, контентных проектов), то в них ситуация диаметрально противоположная — система работает с большим количеством SELECT и малым количеством INSERT/UPDATE. Часто соотношение составляет 10% INSERT-UPDATE/90% SELECT. Надо отметить, что реляционные СУБД достаточно плохо справляются с задачей, которую нам предстояло решить, поэтому мы провели несколько сравнительных тестов системы Cassandra, которая является проверенным решением для задач с интенсивным потоком новых данных. Предлагаем Вашему вниманию результаты тестирования.
На днях мы начали выбор решения для управления данными, которое бы поддерживало высокую производительность на операциях INSERT. Данная задача достаточно часто встречается в различных информационных системах, например, в системах биллинга с большим количеством пользователей и учетных объектов, в системах обмена мгновенными сообщениями, в системах аналитической обработки данных map-reduce. Все данные задачи характеризуются тем, что в них большое количество операций вставки новых объектов в БД и огромный размер БД, при этом обработка данных может производиться как в онлайн так и в пакетном режиме. Если провести параллель в сторону большинства традиционных сайтов (например, контентных проектов), то в них ситуация диаметрально противоположная — система работает с большим количеством SELECT и малым количеством INSERT/UPDATE. Часто соотношение составляет 10% INSERT-UPDATE/90% SELECT. Надо отметить, что реляционные СУБД достаточно плохо справляются с задачей, которую нам предстояло решить, поэтому мы провели несколько сравнительных тестов системы Cassandra, которая является проверенным решением для задач с интенсивным потоком новых данных. Предлагаем Вашему вниманию результаты тестирования.
Итак, коротко о ключевых особенностях Cassandra:
- реализована на Java
- разрабатывается под эгидой Apache Foundation, бесплатная NoSQL СУБД;
- поддерживает SQL-подобный синтаксис (CQL);
- не поддерживает внешние ключи;
- multimaster репликация без ограничений роста;
- линейное увеличение производительности в зависимости от количества узлов.
MySQL является популярной СУБД для Web и, по сути, стандарт de-facto для многих проектов. О плюсах и минусах MySQL можно говорить достаточно долго. В контексте нашей задачи можно говорить о следующих особенностях:
- сложное управление реплицируемыми кластерами;
- плохая масштабируемость на операциях записи;
- низкая производительность на операциях записи.
Конечно, существуют продукты, которые частично решают вышеуказанные ограничения, например, MySQL Cluster, однако, ситуация с производительностью на запись остается прежней.
Тестовая среда
Мы производили тесты в следующей тестовой среде:
- Экземпляр VM: Large 8 cores (Dual E5-2670), 8 GB RAM, 20GB virtio disk
- хранилище NFS/SSD RAID5 Adaptec 6405;
- Сеть хост-хранилище 10G Intel 350;
- Ubuntu 14.04 LVM/Ext4;
- Cassandra 2.0.9 с Oracle Java 7 + cassandra-driver (python);
- MySQL 5.5 из репозитория (INNODB, MYISAM) с модифицированным конфигурационным файлом.
В принципе, было бы интересно провести тесты и для MariaDB, но это будут тесты сравнения реализаций MySQL, а в данном случае вряд ли мы получим радикальные отличия.
Что мы тестируем
Схема таблицы Cassandra:
CREATE TABLE statdata (
host int,
user bigint,
object text,
when timestamp,
value float,
PRIMARY KEY ((host), user, object, when)
) WITH COMPACT STORAGE AND
bloom_filter_fp_chance=0.010000 AND
caching='KEYS_ONLY' AND
comment='' AND
dclocal_read_repair_chance=0.100000 AND
gc_grace_seconds=864000 AND
index_interval=128 AND
read_repair_chance=0.000000 AND
replicate_on_write='true' AND
populate_io_cache_on_flush='false' AND
default_time_to_live=0 AND
speculative_retry='99.0PERCENTILE' AND
memtable_flush_period_in_ms=0 AND
compaction={'class': 'SizeTieredCompactionStrategy'} AND
compression={'sstable_compression': 'LZ4Compressor'};
Схема таблиц MySQL:
create table statdata ( host int,user int, `when` int, object varchar(32), value int) engine=MyISAM; create unique index statdata_idx on statdata (host,user,object,`when`); create table statdata2 ( host int, user int, `when` int, object varchar(32), value int) engine=InnoDB; create unique index statdata_idx on statdata2 (host,user,object,`when`);
Во всех тестах используется составной уникальный ключ host+user+object+when, который состоит из трех int и одного varchar.
Как мы тестируем
Мы выполняли два вида тестов:
- однопоточные тесты;
- многопоточные тесты в 4 потока.
Для Cassandra выполнялось два вида тестов:
- тест с асинхронным выполнением запросов (не ждем ответа от СУБД);
- тест с синхронным выполнением запросов (ждем ответа от СУБД).
Для MySQL так же выполнялось два вида тестов:
- тест с таблицей в MyISAM (statdata);
- тест с таблицей в INNODB (statdata2).
Перед выполнением теста все данные очищаются через TRUNCATE.
Сначала представляем результаты тестирования в один поток (вставка 900K записей):
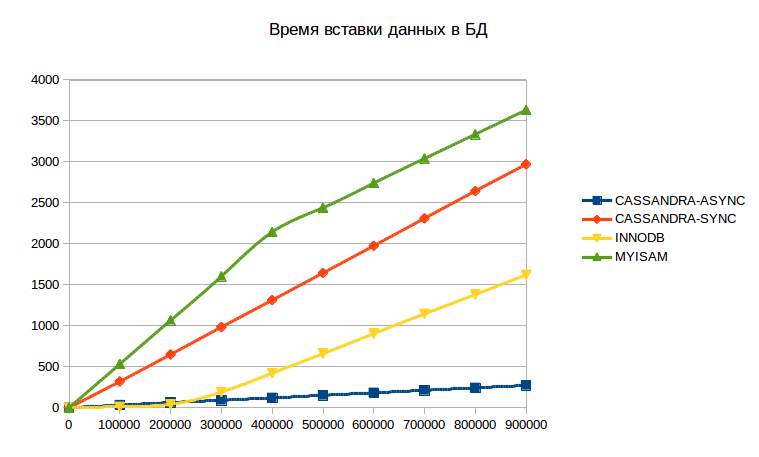
По горизонтальной оси — количество вставленных строк. По вертикальной — время в секундах, которое потрачено на вставку. Как можно видеть Cassandra с асинхронными запросами оставляет остальных участников далеко позади. Cassandra с синхронными запросами ведет себя хуже чем INNODB, но обратите внимание, оба графика для Cassandra линейные. Мы специально продолжали вставки до 10 млн строк и Cassandra продолжала вести себя все так же линейно, в то время как у MySQL начиналась деградация и загибание графиков вверх. Линейность может быть объяснена способом хранения, используемым Cassandra, который позволяет обеспечить рост БД без деградации.
Внизу статьи можно будет найти архив с результатами тестирования, пока же хочется дополнительно отметить, что происходило с процессором и дисковой подсистемой:
- Cassandra async: Iowait ~ 0.25%, IOPS ~ 3, python client — 100% одного ядра;
- Cassandra sync: Iowait ~ 0.01%, IOPS ~ 1, python client — 30% одного ядра;
- MySQL INNODB: Iowait ~ 7%, IOPS ~ 1000, python client — 20-30% одного ядра;
- MySQL MyISAM: Iowait ~ 17%, IOPS ~ 1000, python client — 20-30% одного ядра;
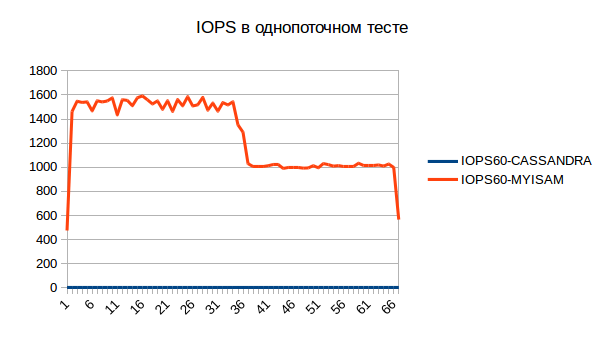
Что можно сказать по этим данным… В случае Cassandra первый тест упирается в скорость клиента и не может получить большую производительность, многопоточный тест позволит получить реалистичный результат. Второй тест для Cassandra упирается в ожидание результата операции от Cassandra. При этом оба теста генерируют мизерную нагрузку на дисковую подсистему.
В случае MySQL мы видим огромное количество IOPS на диск и значительный IOWAIT. Скорее всего упираемся в ограничение MySQL и/или дисковой подсистемы виртуальной машины (хотя IOWAIT не слишком большой, скорее всего именно MySQL). Маловероятно многопоточный тест даст лучшие результаты для MyISAM, возможно что для INNODB будет улучшение.
В случае выполнения любых тестов IOWAIT хранилища был ~0%, что свидетельствует об отсутствии узких мест в системе хранения, которые бы негативно влияли на MySQL.
Представляем результаты тестирования в четыре потока:
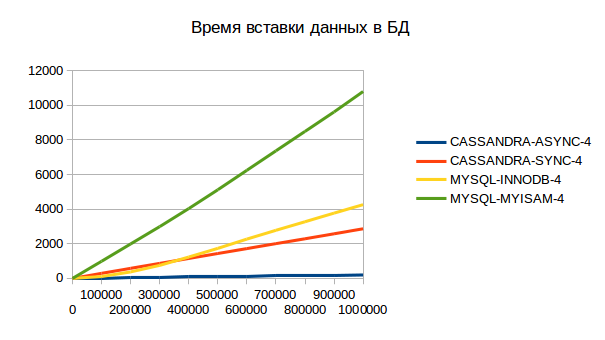
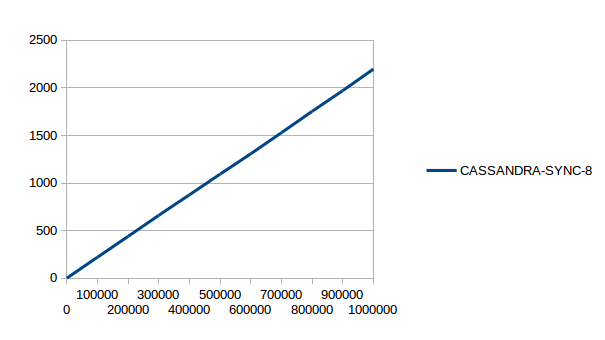
Данные тесты выполняются одновременно четырьмя клиентами, а тест CASSANDRA-SYNC-8 одновременно 8 клиентами. На первом изображении можно увидеть, что в районе 300000×4 (1200000) записей INNODB начинает проигрывать CASSANDRA-SYNC-4, дальше разрыв только увеличивается. При этом INNODB генерирует ~1500 IOPS и загружает систему на 15%, а у Cassandra загрузка и IOPS остаются на мизерном уровне. Для демонстрации возможностей приведен тест CASSANDRA-SYNC-8, в котором в хранилище пишут одновременно 8 клиентов. Как видно, он не слишком отличается от CASSANDRA-SYNC-4.
Наше предположение в том, что можно увеличивать количество клиентов, пока мы не сравнимся с CASSANDRA-ASYNC-4, потому что на этом тесте Cassandra и клиенты полностью утилизировали 8 ядер CPU.
Все журналы тестирования, конфигурационные файлы и тесты на python и shell находятся в архиве: suite
В конце можно добавить, что данные тесты покрывают только случай, когда осуществляется 100% операций вставки в базу, для понимания производительности необходимо так же провести тесты, которые комбинируют чтение и запись одновременно.
Масштабируемость
Модель хранения данных Cassandra подразумевает линейную масштабируемость системы, то есть, увеличив количество узлов в 2 раза, Вы увеличите производительность системы так же в два раза. Для обеспечения отказоустойчивости Cassandra хранит в кластерной системе обычно 3 реплики. Кроме того, линейное увеличение производительности позволяет достаточно просто планировать будущие затраты на вычислительные мощности.
Вместо заключения
Конечно, цель данной статьи не состоит в том, чтобы сказать «выкиньте MySQL», для различных приложений существуют различные решения и реляционные СУБД не зря доминируют на рынке систем управления данными уже 30 лет, это лишь подтверждает, что РСУБД — удачный и удобный инструмент, подходящий для многих задач, однако в свете меняющегося мира, когда объем данных постоянно растет, часто требуются новые инструменты, которые могут уступать гибкости и функциональности реляционным СУБД, но позволяют обрабатывать значительно большие нагрузки и адаптироваться к меняющимся требованиям к производительности.