В этой статье мы рассмотрим, как собрать и использовать Spark Job Server в виде приложения для Docker. Spark Job Server — полезное дополнение Spark, которое позволяет загружать и выполнять задания Spark через Rest API.
Spark Job Server входит в состав популярных дистрибутивов для больших данных, таких как Cloudera CDH5 или Hortonworks, однако, установка полноценного кластера избыточна для целей обучения, разработки или малых вычислительных задач.
В данном руководстве вы узнаете как развернуть готовую среду для разработки, тестирования и продуктового использования Apache Spark без внешних зависимостей с использованием Spark Job Server.
Сборка Spark Job Server с помощью SBT и Docker
Мы будем собирать контейнер Spark Job Server (SJS), который является самодостаточным и может использоваться для работы со встроенным сервером Spark без внешних зависимостей, кроме того, вы можете изменить файл конфигурации и подключить Spark Job Server к существующему кластеру Spark.
Установка Docker
Для успешного выполнения дальнейших действий вам необходимо установить Docker для вашей операционной системы. Если у вас уже настроен и установлен Docker, просто пропустите этот шаг. Если Docker не установлен, установите его по одному из руководств: Ubuntu 16.04 и 18.04, Debian 9 и 10, Centos 7 и приступайте к следующему шагу.
Установка Scala Build Tool
Для сборки потребуется утилита SBT, с помощью которой мы будем собирать контейнер Docker.
Установка SBT для Ubuntu / Debian может быть выполнена следующими командами:
echo "deb https://dl.bintray.com/sbt/debian /" | sudo tee -a /etc/apt/sources.list.d/sbt.list sudo apt-key adv --keyserver hkp://keyserver.ubuntu.com:80 --recv 2EE0EA64E40A89B84B2DF73499E82A75642AC823 sudo apt-get update sudo apt-get install sbt
Установка для CentOS выполняется, как описано ниже:
curl https://bintray.com/sbt/rpm/rpm > bintray-sbt-rpm.repo sudo mv bintray-sbt-rpm.repo /etc/yum.repos.d/ sudo yum install sbt
Теперь скачаем исходные коды SJS с GitHub:
git clone https://github.com/spark-jobserver/spark-jobserver.git cd spark-jobserver/
Сборка базового образа Docker для SJS выполняется с помощью команды sbt docker. Если доступ к Docker доступен только через sudo, запускайте следующую команду, используя sudo:
sbt docker job-server-tests/package
Сборка займет довольно продолжительное время, итогом чего станет генерация контейнера:
$ docker images | grep spark-jobserver velvia/spark-jobserver 0.9.1-SNAPSHOT.mesos-1.0.0.spark-2.3.2.scala-2.11.jdk-8-jdk 3ee46d478a7a 5 days ago 1.41GB
Обратите внимание на версию Spark в имени контейнера, в нашем случае — 2.3.2. Это нам понадобится при доустановке в контейнер необходимых зависимостей для PySpark.
Если вы планируете использовать контейнер для выполнения заданий Spark, реализованных на Scala или Java, можно перейти сразу к разделу «Запуск Spark Job Server». Далее мы рассмотрим как на основании полученного образа собрать подходящий для использования совместно с PySpark.
Сборка контейнера для PySpark
Мы будем использовать полученный образ как основу для генерации целевого образа, который будет поддерживать PySpark.
Создадим каталог для сборки нового контейнера, назовем его spark-jobserver-pyspark:
cd .. && mkdir spark-jobserver-pyspark
Поместим в этот каталог новый Dockerfile, который будет использоваться для построения целевого контейнера:
cat > Dockerfile from velvia/spark-jobserver:0.9.1-SNAPSHOT.mesos-1.0.0.spark-2.3.2.scala-2.11.jdk-8-jdk RUN apt-get install -y python-pip && pip --no-cache-dir install pyhocon pyspark==2.3.2 py4j Ctrl+D
Обратите внимание на то какая версия указана для PySpark, вы должны указать версию, которая соответствует версии Spark в контейнере SJS (первая строка листинга).
Если вам необходимо добавить в контейнер дополнительные файлы, библиотеки и т.п., вы можете дописать необходимые инструкции в Dockerfile.
Теперь вы можете собрать финальный образ:
docker build -t pyspark-job-server:2.3.2 .
Итогом сборки должен стать контейнер, который далее будет использоваться для работы.
Тестирование работоспособности контейнера
Для тестирования контейнера мы запустим его и выполним тестовое задание Spark:
docker run --name sjs -d --rm -p 8090:8090 spark-job-server
Теперь, если вы перейдете в браузере по адресу http://localhost:8090/, то сможете видеть панель мониторинга SJS:
Панель довольно простая и предназначена для просмотра задач, контекстов, загруженных файлов. Так же панель позволяет принудительно завершить задачу или контекст (kill). Все взаимодействие с SJS осуществляется посредством REST API.
Два важных момента:
- Если сервер, на котором вы используете SJS доступен извне, необходимо при запуске использовать -p 127.0.0.1:8090:8090 вместо -p 8090:8090, а доступ к сервису предоставлять через Nginx с аутентификацией, например, через базовую аутентификацию HTTP. Так же лучше использовать защищенный протокол HTTPS. В наших руководствах вы сможете найти как это сделать для Ubuntu и Debian, CentOS с помощью бесплатного сертификата Let’s Encrypt.
- SJS по умолчанию хранит свои данные во встраиваемой СУБД H2, которая не показывает стабильную работу и мы не рекомендуем ее использование за пределами тестирования, далее мы расскажем как заменить H2 на MariaDB.
Подключение СУБД MariaDB
Теперь необходимо установить и настроить MariaDB в виде приложения Docker по инструкции в нашей статье. Если лень читать все подряд, можно выполнить просто следующую команду:
docker run -d --restart=always --name mariadb_1 \
-v /opt/mariadb/data:/var/lib/mysql \
-v /opt/mariadb/etc:/etc/mysql/conf.d \
-v /opt/mariadb/logs:/var/lib/mysql/logs \
-e MYSQL_ROOT_PASSWORD=secret \
-p 127.0.0.1:3306:3306 mariadb:10.3
Дождитесь окончания инициализации MariaDB (5-10 секунд). Теперь создадим базу данных для SJS:
docker run -it --rm --link mariadb_1:mysql mariadb:10.3 mysql -hmysql -uroot -psecret mysql> CREATE USER 'jobserver'@'%' IDENTIFIED BY 'secret'; mysql> CREATE DATABASE spark_jobserver; mysql> GRANT ALL ON spark_jobserver.* TO 'jobserver'@'%'; mysql> FLUSH PRIVILEGES; CTRL^D
Проверьте соединение с созданной БД из под нового пользователя:
docker run -it --rm --link mariadb_1:mysql mariadb:10.3 mysql -hmysql -ujobserver -psecret spark_jobserver -e 'SELECT VERSION();'
Теперь скопируем файл конфигурации для SJS из контейнера в файловую систему сервера:
docker cp sjs:app/docker.conf .
Остановите сервер SJS, пока что он не требуется, в следующий раз мы запустим его уже с бэкендом MySQL:
docker stop sjs
Модифицируем конфигурационный файл docker.conf для работы c MySQL. В новых версиях SJS в конфигурационном файле могут быть новые параметры, поэтому убедитесь, что они будут перенесены в целевой конфигурационный файл. На момент публикации конфигурационный файл содержит следующие параметры:
spark {
master = "local[*]"
master = ${?SPARK_MASTER}
submit.deployMode = "client"
job-number-cpus = 4
jobserver {
port = 8090
jobdao = spark.jobserver.io.JobSqlDAO
context-creation-timeout = 60000
context-per-jvm = true
# ----------------------
# настройки MYSQL
sqldao {
slick-driver = slick.driver.MySQLDriver
jdbc-driver = com.mysql.jdbc.Driver
jdbc {
url = "jdbc:mysql://mysql/spark_jobserver"
user = "jobserver"
password = "secret"
}
dbcp {
maxactive = 20
maxidle = 10
initialsize = 10
}
}
}
context-settings {
num-cpu-cores = 4
memory-per-node = 8192m
passthrough {
}
}
home = "/spark"
}
deploy {
manager-start-cmd = "app/manager_start.sh"
}
# ---------------------
# создание таблиц MySQL
flyway.locations="db/mysql/migration"
Обратите внимание на параметры spark.job-number-cpus, spark.context-settings — они должны быть настроены для соответствия вашему узлу, на котором вы запускаете SJS.
Так же, обратите внимание, что вместо local[*] для параметра spark.master можно указать адрес действующего мастера Spark, в том числе и через переменную docker -e SPARK_MASTER=URI. По умолчанию, будет использоваться встраиваемый сервер Spark, что вполне подходит при выполнении вычислений на одном узле.
Теперь можно запустить SJS с бэкендом MySQL:
docker run --restart=always --link mariadb_1:mysql \
-v $(pwd)/docker.conf:/app/docker.conf \
-v $(pwd)/data:/tmp/data \
--name sjs -d \
-p 8090:8090 spark-job-server
Если сервер, на котором вы используете SJS доступен извне, необходимо при запуске использовать -p 127.0.0.1:8090:8090 вместо -p 8090:8090, а доступ к сервису предоставлять через Nginx с аутентификацией, например, через базовую аутентификацию HTTP. Так же лучше использовать защищенный протокол HTTPS. В наших руководствах вы сможете найти как это сделать для Ubuntu и Debian, CentOS с помощью бесплатного сертификата Let’s Encrypt.
Запуск приложения Spark в Spark Job Server
Для дальнейшего тестирования SJS загрузим тестовые приложения Spark, которые поставляются в составе SJS:
JOBFILE=$(find ../spark-jobserver/job-server-tests/target/ -name 'job-server-tests*.jar') curl -X POST localhost:8090/binaries/test -H 'Content-Type: application/java-archive' --data-binary @$JOBFILE
Запустим приложение подсчета слов:
curl -d "input.string = a b c a b see" "localhost:8090/jobs?appName=test&classPath=spark.jobserver.WordCountExample"
{
"duration": "Job not done yet",
"classPath": "spark.jobserver.WordCountExample",
"startTime": "2019-04-17T14:44:08.435Z",
"context": "78c96fd8-222f-4a5a-af24-10171c42065b-spark.jobserver.WordCountExample",
"status": "STARTED",
"jobId": "8a99ed4e-8a54-4ab0-b61e-fbe2bb05bda8",
"contextId": "f2b0dbea-d95f-4190-9b37-a87a055d1acc"
}
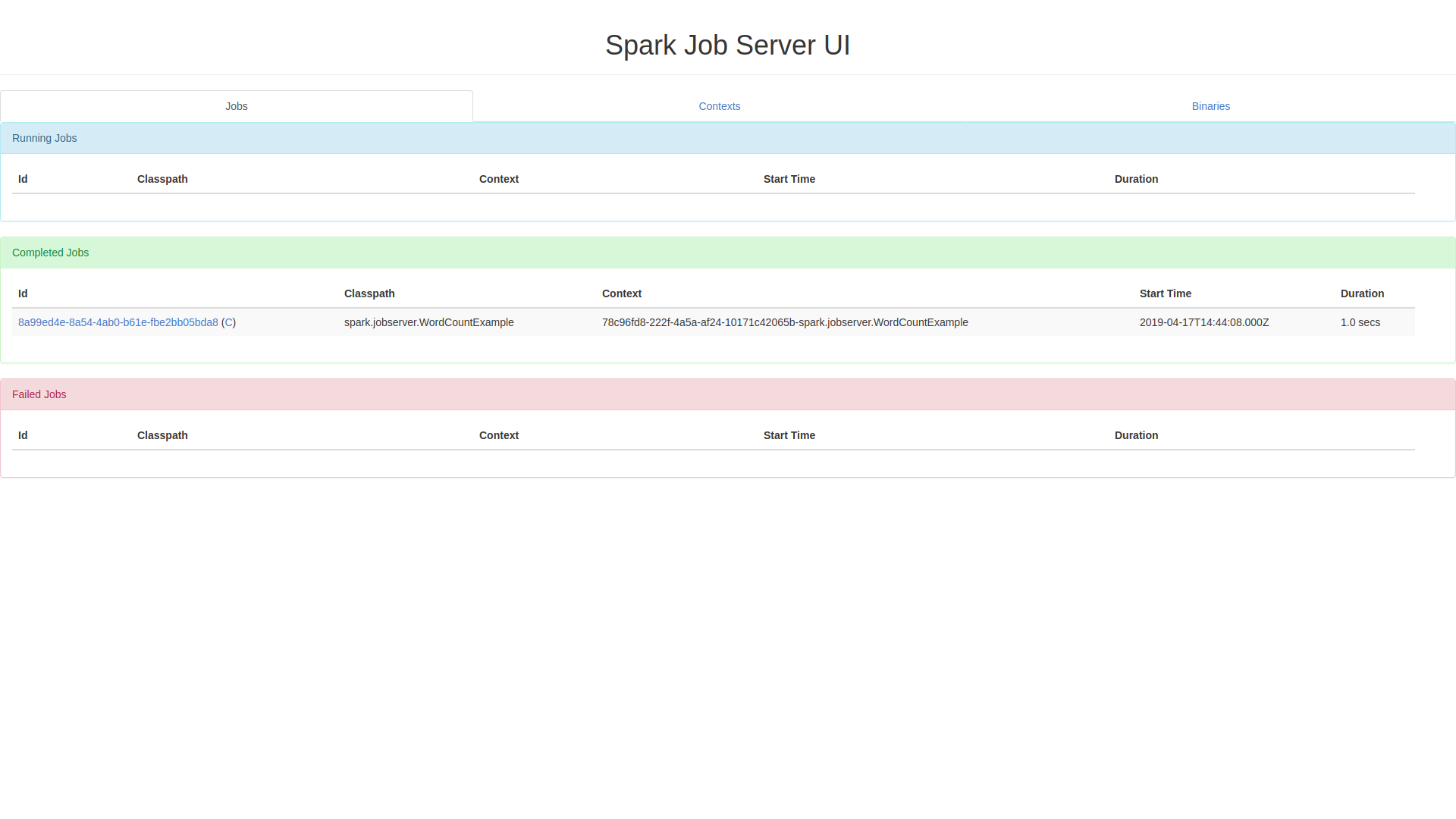
Теперь можно отслеживать состояние задачи по JobID, как только задача завершится, вы сможете увидеть результат ее выполнения:
curl localhost:8090/jobs/8a99ed4e-8a54-4ab0-b61e-fbe2bb05bda8
{
"duration": "1.0 secs",
"classPath": "spark.jobserver.WordCountExample",
"startTime": "2019-04-17T14:44:08.000Z",
"context": "78c96fd8-222f-4a5a-af24-10171c42065b-spark.jobserver.WordCountExample",
"result": {
"a": 2,
"b": 2,
"see": 1,
"c": 1
},
"status": "FINISHED",
"jobId": "8a99ed4e-8a54-4ab0-b61e-fbe2bb05bda8",
"contextId": "f2b0dbea-d95f-4190-9b37-a87a055d1acc"
}
Этот же результат можно увидеть и через браузер:

Запуск приложения PySpark
Создадим приложение SJS для Spark по инструкции:
mkdir job
cat > job/__init__.py
from sparkjobserver.api import SparkJob, build_problems
class WordCountSparkJob(SparkJob):
def validate(self, context, runtime, config):
if config.get('input.strings', None):
return config.get('input.strings')
else:
return build_problems(["config 'input.strings' not found"])
def run_job(self, context, runtime, data):
return context._sc.parallelize(data).countByValue()
Ctrl^D
Скопируем зависимости для взаимодействия с API SJS в проект:
cp -R ../spark-jobserver/job-server-python/src/python/sparkjobserver .
Создадим файл для сборки пакета Python:
cat > setup.py
from setuptools import find_packages, setup
setup(
name='job',
packages=['job','sparkjobserver'],
include_package_data=True,
)
Ctrl^D
Создадим пакет приложения:
python setup.py bdist_egg running bdist_egg running egg_info writing job.egg-info/PKG-INFO writing top-level names to job.egg-info/top_level.txt writing dependency_links to job.egg-info/dependency_links.txt reading manifest file 'job.egg-info/SOURCES.txt' writing manifest file 'job.egg-info/SOURCES.txt' installing library code to build/bdist.linux-x86_64/egg running install_lib running build_py creating build/bdist.linux-x86_64/egg creating build/bdist.linux-x86_64/egg/sparkjobserver copying build/lib.linux-x86_64-2.7/sparkjobserver/subprocess.py -> build/bdist.linux-x86_64/egg/sparkjobserver copying build/lib.linux-x86_64-2.7/sparkjobserver/api.py -> build/bdist.linux-x86_64/egg/sparkjobserver copying build/lib.linux-x86_64-2.7/sparkjobserver/__init__.py -> build/bdist.linux-x86_64/egg/sparkjobserver creating build/bdist.linux-x86_64/egg/job copying build/lib.linux-x86_64-2.7/job/__init__.py -> build/bdist.linux-x86_64/egg/job byte-compiling build/bdist.linux-x86_64/egg/sparkjobserver/subprocess.py to subprocess.pyc byte-compiling build/bdist.linux-x86_64/egg/sparkjobserver/api.py to api.pyc byte-compiling build/bdist.linux-x86_64/egg/sparkjobserver/__init__.py to __init__.pyc byte-compiling build/bdist.linux-x86_64/egg/job/__init__.py to __init__.pyc creating build/bdist.linux-x86_64/egg/EGG-INFO copying job.egg-info/PKG-INFO -> build/bdist.linux-x86_64/egg/EGG-INFO copying job.egg-info/SOURCES.txt -> build/bdist.linux-x86_64/egg/EGG-INFO copying job.egg-info/dependency_links.txt -> build/bdist.linux-x86_64/egg/EGG-INFO copying job.egg-info/top_level.txt -> build/bdist.linux-x86_64/egg/EGG-INFO zip_safe flag not set; analyzing archive contents... creating 'dist/job-0.0.0-py2.7.egg' and adding 'build/bdist.linux-x86_64/egg' to it removing 'build/bdist.linux-x86_64/egg' (and everything under it)
Загрузим приложение PySpark на сервер:
JOBFILE=$(find -name *.egg) curl --data-binary @$JOBFILE -H 'Content-Type: application/python-archive' localhost:8090/binaries/my_py_job
Создадим контекст для исполнения задачи:
curl -X POST "localhost:8090/contexts/py-context?context-factory=spark.jobserver.python.PythonSessionContextFactory"
{
"status": "SUCCESS",
"result": "Context initialized"
}
Запустим задачу:
curl-d 'input.strings = ["a", "b", "a", "b" ]' "localhost:8090/jobs?appName=my_py_job&classPath=job.WordCountSparkJob&context=py-context"
{
"duration": "Job not done yet",
"classPath": "job.WordCountSparkJob",
"startTime": "2019-04-17T15:17:58.397Z",
"context": "py-context",
"status": "STARTED",
"jobId": "932bc1d3-011e-459b-9618-111832a1ef87",
"contextId": "555eb5ba-9951-4917-982b-8b944cc782dc"
}
curl localhost:8090/jobs/932bc1d3-011e-459b-9618-111832a1ef87
{
"duration": "1.0 secs",
"classPath": "job.WordCountSparkJob",
"startTime": "2019-04-17T15:17:58.000Z",
"context": "py-context",
"result": {
"a": 2,
"b": 2
},
"status": "FINISHED",
"jobId": "932bc1d3-011e-459b-9618-111832a1ef87",
"contextId": "555eb5ba-9951-4917-982b-8b944cc782dc"
}
Теперь вы можете использовать SJS для работы со Spark с помощью REST API. Дальнейшие инструкции по работе с PySpark и SJS можно найти в профильной статье. Если вы планируете использовать Scala, вам следует обратиться к примерам для Scala, если Java — к примерам для Java.
Заключение
Spark Job Server — мощный инструмент, который позволяет работать с кластером или локальным вычислителем Spark эффективно. Уникальные возможности использования постоянных контекстов Spark позволяют запускать родственные задачи быстро с уменьшенными накладными расходами.
За дальнейшими инструкциями по использованию SJS мы рекомендуем обратиться к официальной документации.